12 March 2026
Filter by area of interest
All
Filter by content type











05 December 2025



21 November 2025


07 November 2025

24 October 2025


15 October 2025

18 September 2025




.png?width=596&name=Blog%20Thumbnail%20(1920%20x%201080%20px).png)
.png?width=596&name=image%20(3).png)


10 July 2025












.jpg?width=596&name=_ZHIP%20KARKO%20(2).jpg)





.png?width=596&name=Copy%20of%20Fuel%20Savings%2c%20Lower%20Emissions%2c%20Better%20Ratings%20-New%20Incentives%20for%20ESD%20Adoption!%20(685%20x%20435%20px).png)



22 October 2024
.png?width=596&name=age%20trigger%20-edm%20(1324%20x%20783%20px).png)






.png?width=596&name=Age-trigger-blog%20(1).png)

.png?width=596&name=Copy%20of%20Partnership%20banner%20for%20blog%20post%20(1).png)

19 June 2024







.png?width=596&name=ZHIP%20Learning%20Seaman%20(1).png)

.png?width=596&name=Untitled%20design%20(9).png)
.png?width=596&name=Blog%20banner%201%20%20(1).png)
21 March 2024
.jpg?width=596&name=Crew%20welfare%204%20(1).jpg)
20 March 2024





08 February 2024

.png.webp?width=596&name=portosudeste_portosudeste-Blog%20(1).png.webp)


13 December 2023







28 September 2023






01 August 2023
.png.webp?width=596&name=MicrosoftTeams-image%20(2).png.webp)
24 July 2023





29 June 2023
.png.webp?width=596&name=Leaders%20Forum%20Singapore%2023%20-%20video%20recording%20blog%201%20(2).png.webp)
.png.webp?width=596&name=MicrosoftTeams-image%20(6).png.webp)
20 June 2023
.png-1.webp?width=596&name=MicrosoftTeams-image%20(2).png-1.webp)



.png.webp?width=596&name=MicrosoftTeams-image%20(10).png.webp)
.png.webp?width=596&name=RightShip%20Ending%20Scene%20(002).png.webp)

20 April 2023
.webp?width=596&name=Screening-trade_finance-blog2-blog.png%20(1).webp)

.png.webp?width=596&name=seafarer_abandonment-BLOG%20(1).png.webp)
27 March 2023





14 February 2023

14 February 2023



07 February 2023



23 January 2023
.webp?width=596&name=inspections-heatmapjan-blog-cover.png%20(1).webp)
19 January 2023


12 December 2022


07 November 2022


04 October 2022

27 September 2022

11 September 2022
.png.webp?width=596&name=inspections-heatmap-blog-cover%20(1).png.webp)
11 August 2022




.png.webp?width=596&name=andrew-interview-blog-cover%20(1).png.webp)








23 May 2022






.png.webp?width=596&name=inspections-heatmap-blog-cover%20(5).png.webp)
06 April 2022

.webp?width=596&name=tam-article-1-blog-cover.png%20(1).webp)


03 February 2022
.png.webp?width=596&name=inspections-heatmap-blog-cover%20(4).png.webp)
23 January 2022
.png.webp?width=596&name=lloyds-list-steen-video-promo-blog-cover%20(1).png.webp)
16 January 2022



13 December 2021

10 November 2021


26 October 2021

25 October 2021

18 October 2021
.png.webp?width=596&name=ai-based-vessel-risk-profiling-blog-cover%20(1).png.webp)

12 October 2021



30 September 2021

28 September 2021

28 September 2021


03 September 2021
.png.webp?width=596&name=microsoftteams-image-19%20(1).png.webp)
27 August 2021



01 August 2021








.webp?width=596&name=human-side-launch-banner.png%20(1).webp)
.png-1.webp?width=596&name=istock-524176098_screen_adjusted%20(1).png-1.webp)



14 January 2021


29 November 2020
.png.webp?width=596&name=istock-524176098_screen_adjusted%20(1).png.webp)
29 November 2020

23 November 2020


17 November 2020


22 October 2020
.webp?width=596&name=image.png%20(1).webp)
14 September 2020
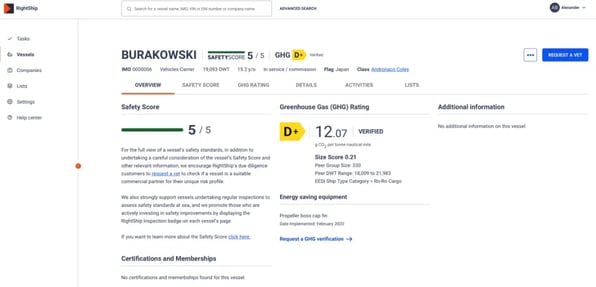
11 September 2020

03 September 2020



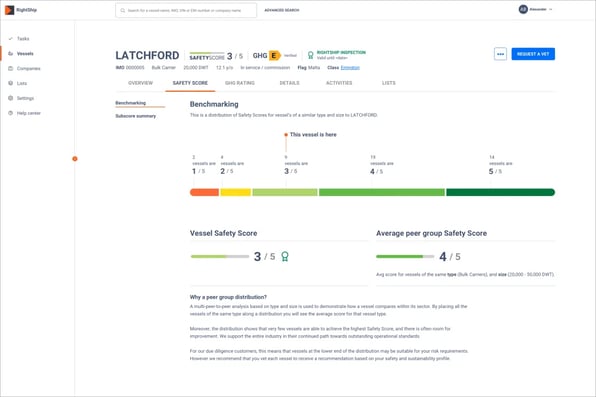
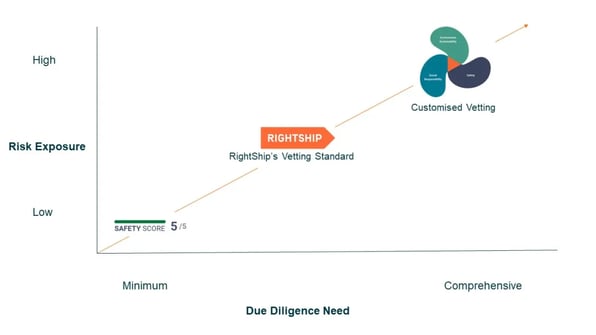








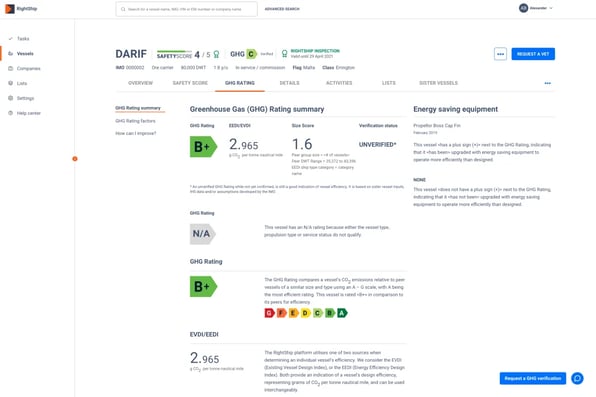

02 April 2020


29 February 2020
.png.webp?width=596&name=csp201113_1026%20(1).png.webp)
01 January 2020


31 July 2019


29 April 2019

27 February 2019

25 October 2018




